[DE] spark vs hive vs hadoop vs rdbms 간단 정리
hive
- hive는 SQL언어를 하둡 위에서 사용할 수 있는 쿼리 엔진이다.
- Metastore database 저장소에 스키마정보, 통계정보 등을 저장하고있는데, 이 정보를 통해 최적화 작업을 수행한다.
- hadoop에 접근하기 떄문에 레코드(행) 단위로 접근 하면 성능이 오히려 떨어질 수 있다.
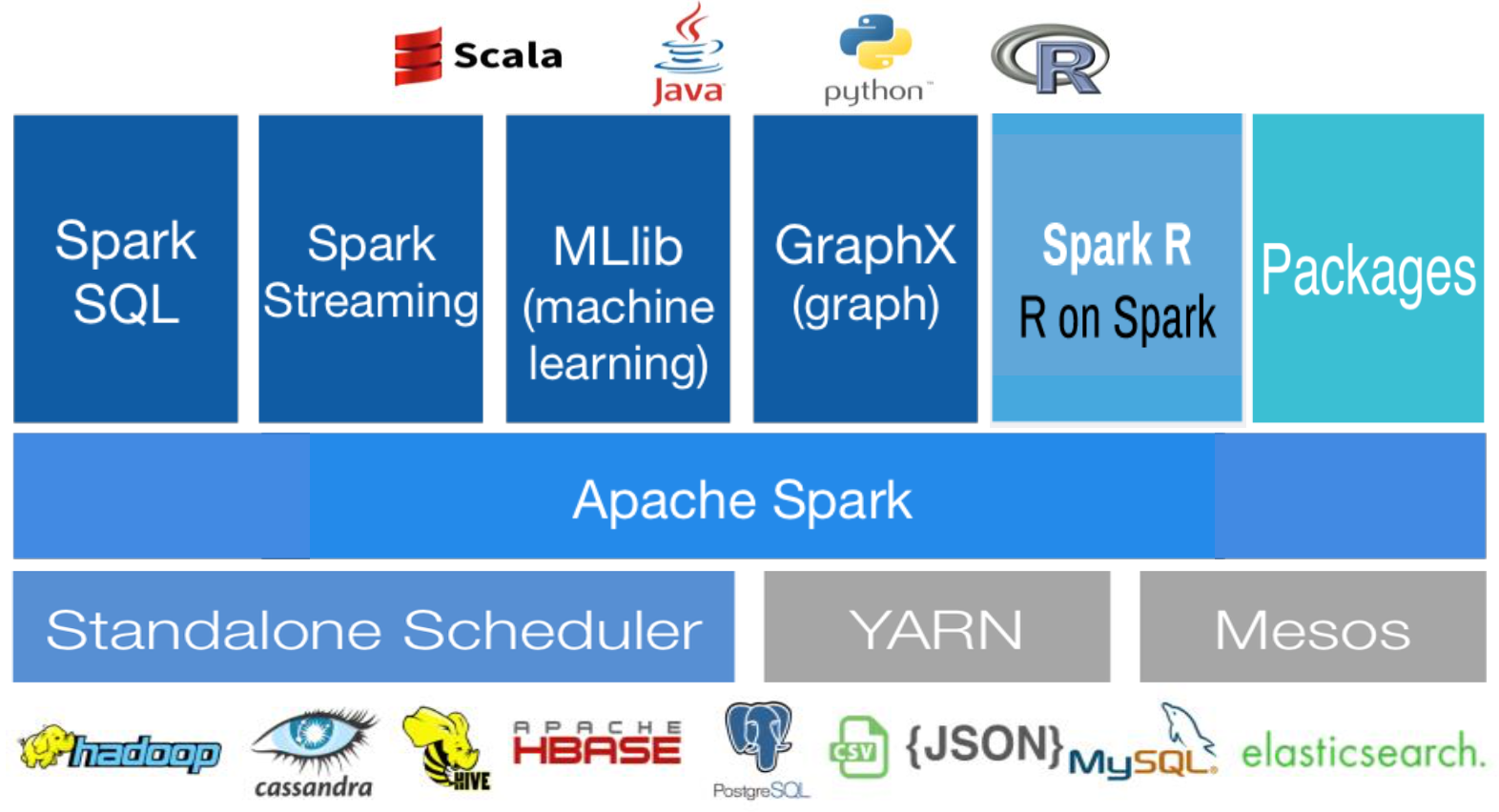
spark
- In-Memory 컴퓨팅 (Disk 기반도 가능)
- RDD (Resilient Distributed DataSet) 데이터모델
- 다양한 개발언어 지원 (Scala, Java, Python, R, SQL)
- hive, pig등등 저장소에 접근하기 위한 상당히 많은 오픈소스들이 나왔고 오픈소스들 간의 다르고 유사한 부분들을 통합시키고자 나옴

hadoop
- 분산 저장소 역할
- 100메가 이상의 블록단위로 데이터가 저장된다.
- 에코시스템에 기본적으로 hdfs와 yarn이 있다.
- 하둡 파일(저장)시스템과 yarn이라는 처리 시스템이 합쳐져있는것

참고
[1] 모두의 연구소
이 문서는
jhy156456에 의해 작성되었습니다.
마지막 수정 날짜:2022-12-14 14:25:00