[spark] spark란? spark 기본 개념
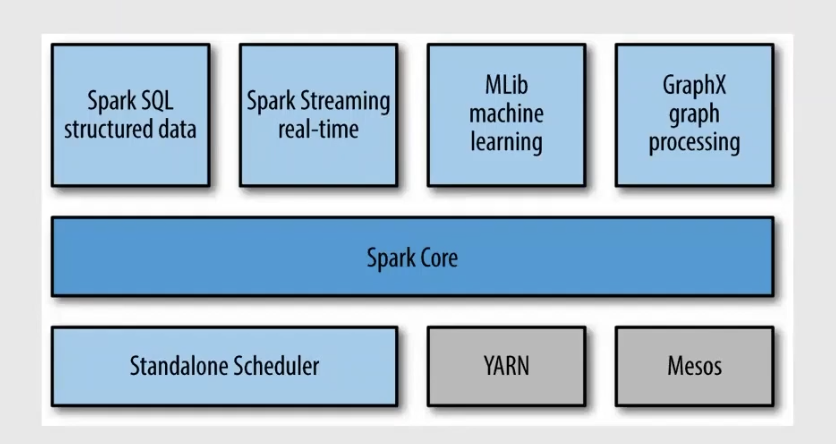
spark란?
- 범용적인 목적을 지닌 분산 클러스터 컴퓨팅 프레임워크
- 내 결함성, 병렬처리를 언어 수준에서 처리가 가능
- Java,Python, R 등 다양한 언어지원
- python은 pyspark 라이브러리를 통해 사용 가능
- yarn(hadoop의 hdfs같은개념) 이라는 리소스 매니저가 리소스에대해 관리해줌
- 리소스를 클러스터하면서 어떻게 애플리케이션을 실행할건지?관리
- 어떻게 spark애플리케이션이 기동될건지 관리
소프트웨어 엔지니어링 관점
- 메모리 가격에 비해 Disk I/O비용은 상대적으로 크다
프레임워크 관점
- 통합된 파이프라인 구성
- 단순화된 데이터 플로우와 재사용 가능
데이터 추상화 관점
- 분산 환경에 최적화 되어있는 RDD를 통한 추상화 레이어
프로젝트 텅스텐
카탈리스트 옵티마이저
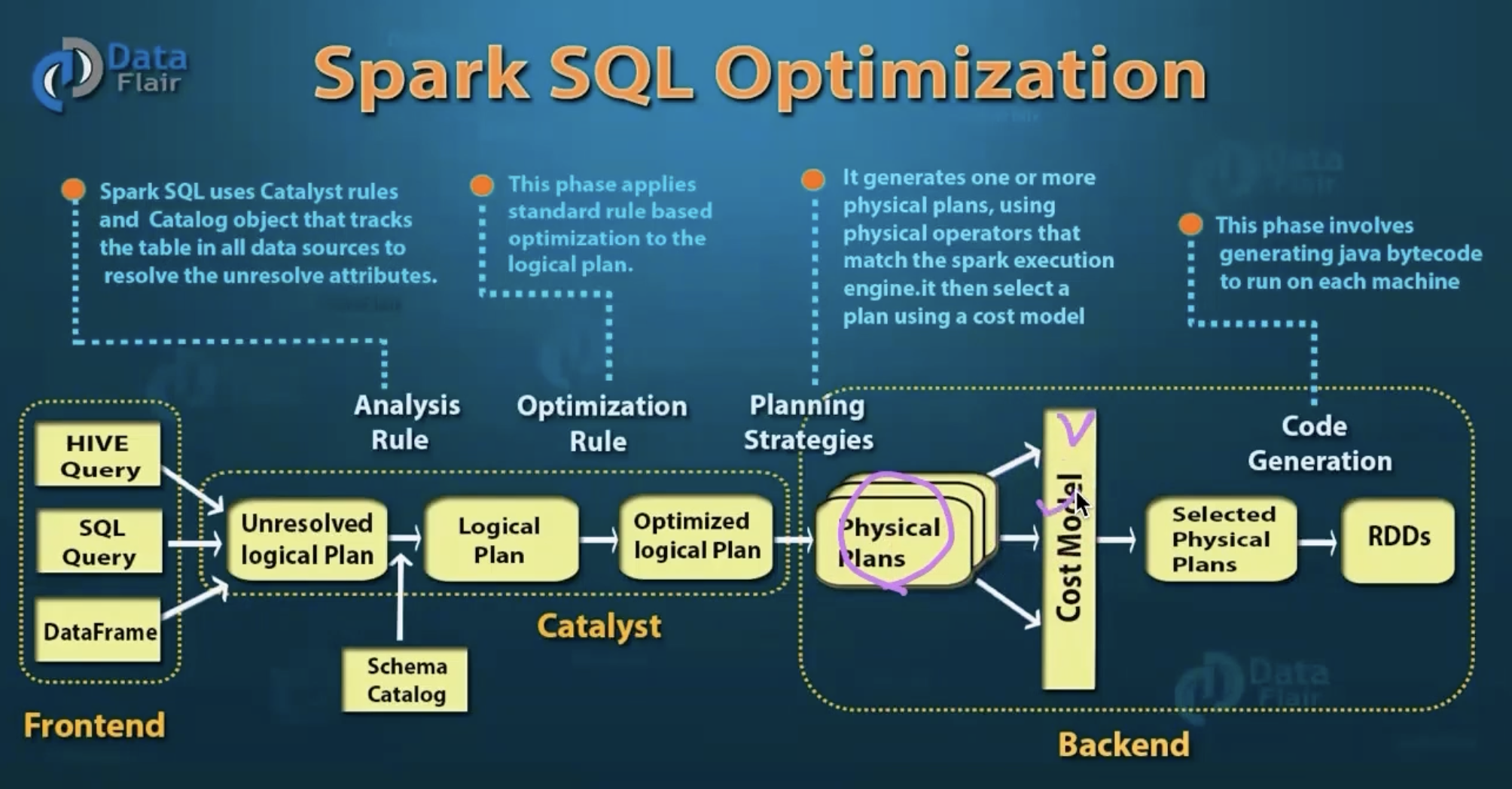
- 카탈리스트가 쿼리를 읽어와서, 로지컬 플래닝을 짜준다.
- 어떻게 조인하고, 어디서 읽어올지
- 로지컬 플랜에서 메타데이터를 통해 계산하여 데이터 이동에 걸릴시간을 계산한다
- 수행 후 실제로 실행되는 jar파일 코드가 생성 되고 분산환경에 배포됨
- 각 노드들에서 워커노드들이 데이터를 읽어들이고 수행하게 된다.
https://www.slideshare.net/databricks/sparksql-a-compiler-from-queries-to-rdds
스파크 애플리케이션 동작 방식
클러스터 관리자(yarn)에 의해 어떻게 동작하는가?
- hadoop 컴포넌트인 yarn이라고 하는 리소스 관리자에게 spark가 애플리캐이션을 짜서 위임 시켜준다.
- yarn은 이미 떠있음
- spark를 통해 submit하는것
스파크 드라이버
- 클러스터 매니저게에 할당 받아서 내가 수행하는 프로그램을 관리한다
- 스파크 익스큐터는 실제 할당된 작업을 수행하는 프로세스
이 문서는
jhy156456에 의해 작성되었습니다.
마지막 수정 날짜:2022-12-14 14:25:00